General
Addressing The $125bn First Party Fraud Challenge using AI & Machine Learning
15 Jul 2024
Founder & CTO, Ensemble
Financial Crime & Payments Practice Lead, Ensemble

“First-party fraud”, sometimes referred to as “friendly fraud”, is any fraud that is initiated directly by a customer, rather than a third party.
This is a growing thorn in the side of fincrime teams. It is estimated that just one variation of first-party fraud, chargeback fraud, amounts to over $125 billion in annual losses globally, affecting merchants, businesses, banks, and consumers alike.
In this article, we will explain why we believe businesses are struggling to tackle this problem using their existing fincrime technology and processes. We will make the case for how levelling up their use of analytics, data science, machine learning and AI can help them to reduce their exposure to it, and explain some of the steps on this journey.
What Is First-Party Fraud?
First-party fraud has the following characteristics:
Firstly, it is fraud that is committed directly by a “legitimate” customer using their own personal details, rather than by a nefarious third party impersonating someone else.
Secondly, the deceit lies in a falsified allegation rather than in the transaction itself. The transaction is legitimate at the time it occurs but is disputed later by the customer under false pretences.
Third, this type of fraud occurs some time after the transaction, with the transaction appearing legitimate until the perpetrator disputes it, potentially many weeks later.
This combination of features makes first-party fraud particularly difficult to detect and respond to, as it often falls outside of fraud detection systems that are optimised for validating identities and detecting fraud at the time of transaction. It is an entirely different and much more difficult class of problem to solve for.
The challenging nature of this was noted as far back as 2019, when the UK’s Credit Industry Fraud Avoidance System (CIFAS) stated in its report “In Tackling First-Party Fraud” that “It may never be possible to eliminate first-party fraud; there will always be some people willing to attempt to defraud companies.”
All is not lost however. We believe that by analysing their data in more sophisticated ways, businesses can reduce losses and detect instances of this fraud that might otherwise fly under the radar of their existing fincrime systems and processes.
We will discuss and demonstrate this in more detail later in this article, but first, we will delve deeper into the problem and explain why it is a high value problem to solve.
The First-Party Fraud Problem
First-party fraud can take various forms, including:
-
Fraudulent Chargebacks: This occurs when a customer makes a legitimate purchase, but then disputes the charge after the fact in an attempt to secure the product or service for free;
-
Refund and Promotion Abuse: This is where customers exploit return and promotion policies that they are not entitled to in order to get something without paying full price;
-
Wardrobing: This retail fraud involves buying something with the intention of using it once or twice and then returning it for a full refund;
-
Application Fraud: A person uses their own identity and documentation to apply for a financial product, such as a loan, and then later claims their credentials were stolen by a third party;
-
Sleeper Fraud: A customer behaves normally for a long period to evade detection and build up credit limits, then suddenly uses the credit and disappears with no further communication.
According to an annual chargeback field report, 76% of merchants saw an increase in “friendly fraud” in 2021, partly due to the global COVID-19 pandemic. The CEO of Chargeback911, Monica Eaton, commented, “We are well past the confines of the pandemic and that number remains the same. More action is needed to quell the ongoing rise in chargeback abuse.”
In a survey conducted by Source in 2023, an alarming 52% of Generation Z respondents admitted they would commit first-party fraud if they knew there would be no consequences. Shockingly, 35% of respondents admitted they had already engaged in such fraudulent activities, such as using buy-now-pay-later options with no intention of paying for the purchase.
Shortfalls In Legacy Technology
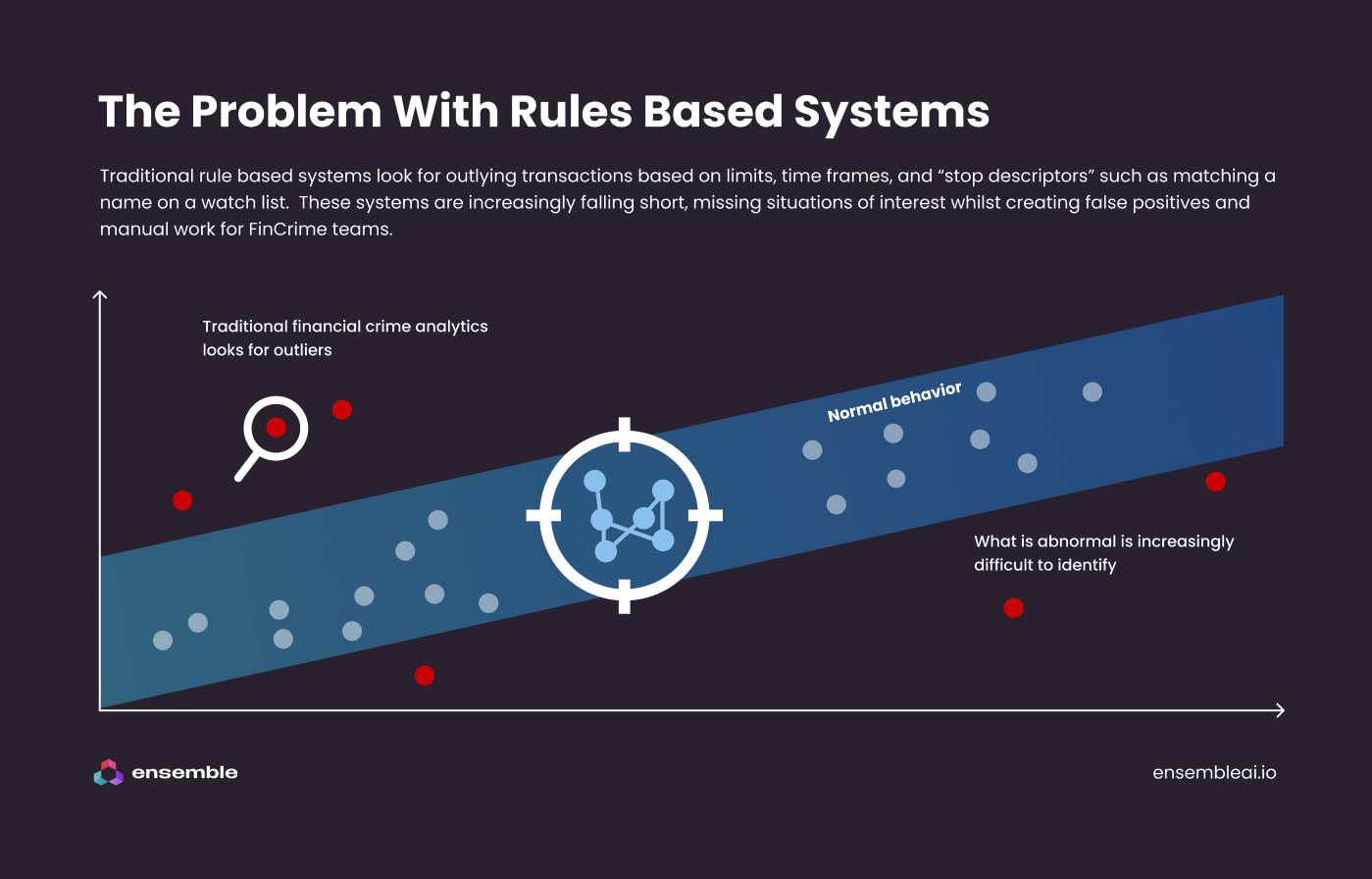
Businesses are attempting to combat these classes of fraud with their existing fincrime detection technology, but in many cases they are finding that it isn't sophisticated enough to identify threats of this nature.
Many of these systems rely on simple business rules to detect suspicious transactions. They are unable to detect more complex scenarios such as the above which require searching for subtle patterns across multiple behavioural data points incorporating a time based element.
These legacy systems also do not incorporate advanced statistics, pattern recognition and machine learning capabilities, and are not able to identify complex and evolving situations over time.
The data required to detect this type of fraud also often lives in siloed systems such as eCommerce platforms or back office ERP systems. If we take product returns for instance, these are often logged by a warehouse into a back end logistics system that issues the refund through a finance system. Fincrime systems do not typically integrate this type of data into their decision making and risk models.
This adds up to a situation where legacy systems do not have either the smarts or the data to accurately detect first-party fraud.
This Cannot Be Solved With Off The Shelf Software
Though more modern fincrime systems are making strides in this area, we think that using an off the shelf software package or SaaS service to identify fraud of this nature is eventually doomed to fail. We say this for a number of reasons:
Breadth Of Data Required
The data needed to successfully identify these classes of fraud is spread across multiple systems. In order to identify instances of fraud, we need a joined-up and current view of data from across the business, including customer demographics, transaction history and information on products, promotions, logistics, and other business processes. This complete and single view of the customer is hard for any single fincrime system to achieve in isolation.
Sophistication Of Analysis Required
In order to identify complex fraud of this nature, we need to turn towards more advanced statistical analysis, data science, machine learning and AI. Though fincrime technology will have some capability in this area, it will never be as sophisticated or flexible as a data scientist could achieve working directly with data in an analytics environment, using a flexible programming language such as Python and the latest numerical and machine learning libraries.

Variations Amongst Businesses
Every business is different. What constitutes a normal transaction vs an outlier varies from business to business, and each business is exposed to different profiles of fraud risks. Though software packages have a degree of configurability, they are not always flexible enough to account for the subtle differences between businesses and their threat profile to both allow them to identify all fraud whilst simultaneously minimising false positives.
Continually Evolving Threats
The fraudsters themselves are also changing and evolving. If we put a system into place that defends against a certain type of fraud, the fraudsters will move onto new scams and attack methods. This means that businesses would constantly be implementing new and upgraded systems with lengthy delays in a never ending game of cat and mouse.
A Better Approach - Building Data Science Muscle
We believe that solving this problem requires a degree of bespoke data engineering and data science work. It involves getting your hands dirty with your own business data, and analysing it using statistical and data science techniques combined with your your own knowledge of your own business and threat profile.
Using data in this way may or may not be a new capability for your business or fincrime team, but the business case for doing so can be huge when you consider the exposure to financial loss, compliance costs and reputational risk.
At a high level, the approach involves bringing your own business data together into a centralised data warehouse where it is organised ready for analysis. Your data analysts and data scientists will then be able to analyse your own data to search for patterns of interest and quantify their impact on your business. Once identified, reports and dashboards can be created to monitor for these situations going forward.
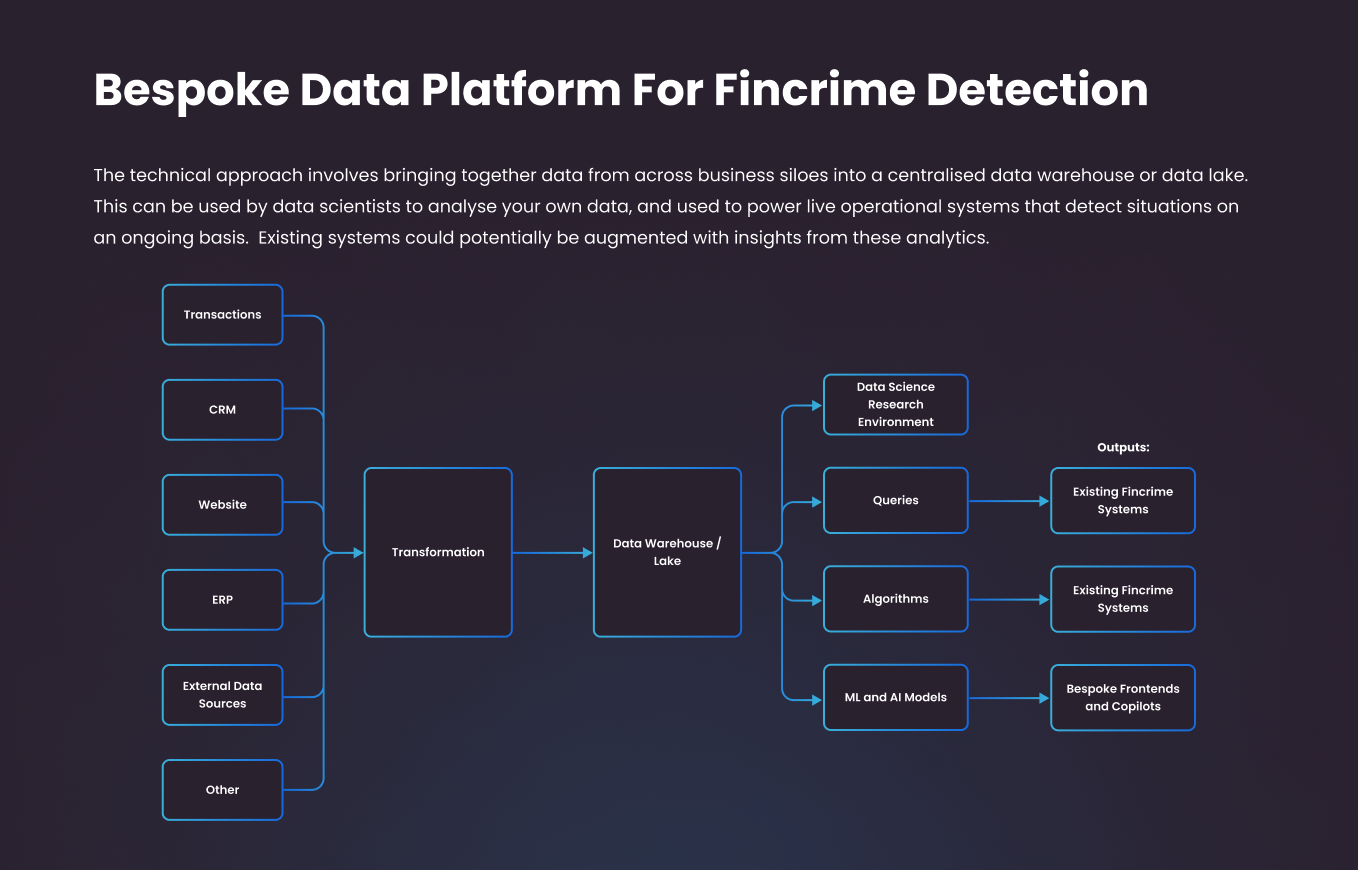
The components of this solution include:
Central Data Warehouse or Data Lake
A data warehouse or data lake is a centralised repository of data from across your business. It includes customer data, transaction data, and other data captured as a result of your business processes. The idea behind the warehouse is to consolidate all data into one location where it can be utilized to power business intelligence reports, dashboards and other analytics scenarios. Although this is a mature practice in business more generally, adding financial crime use cases against your data warehouse may be a new initiative for your team.
Data Engineering
Next, we need to extract information from various business systems into the centralised data warehouse or data lake. The information extracted could include transactions, customer demographics, product offers, orders, returns, etc. Depending on the maturity of your current data warehouse, this data may already be present or you may need to arrange to integrate it to meet your financial crime monitoring scenarios.
Data Science
Once the data is in the data lake, a data scientist can analyze it, applying mathematical and statistical techniques to understand datasets and identify anomalies. Typically, they would use a data science notebook and programming languages such as Python or R to work with the raw data and uncover risks and instances of fraud in their historical datasets. In the exeample below, we analuysed a real customer dataset to identify situations of account takeover and better understand how they are occuring:

Machine Learning
Identifying instances of fraud is relatively straightforward when we know what to look for and when the scenarios are simple. However, first-party fraud situations are much more complex to uncover, potentially requiring tends or data points to properly classify. Machine learning allows us to provide a labeled set of fraudulent transactions to a model, which can then automatically classify future transactions as potentially fraudulent as part of an operational system. This allows us to detect patterns and clusters which are too complex for humans to find by hand.
AI and Large Language Models
Recent innovations in AI and large language models have tremendous potential to improve outcomes in this area. For instance, we can integrate unstructured information into our decision-making processes, enriching customer profiles with non-standard sources of data. Please see our recent article on using LLMs to enrich customer profiles for more detail on this approach.
Graph Analytics
In order to make a decision about a given transaction or customer, it is important to investigate all of the entities linked to the person. This could include their linked accounts, delivery addresses, device details and other context. Graph databases make this type of analysis easier and faster to carry out and should be an important part of your fincrime analytics stack.

Operational Reporting and Tooling
Once a potential risk or fraud vector has been identified, the business will need to implement a report, dashboard, or system to detect future instances of fraud and prevent it at source. This could be achieved by a data analyst building a report or dashboard, or a data scientist or software developer building a more interactive operational application to support business users.
Conclusion
First-party fraud is a growing problem for businesses of all kinds. It involves any situation where a fraud is carried out by a real customer as opposed to a nefarious third party impersonating someone else.
We have explained how legacy Fincrime technology falls short in the task of identifying this type of fraud. The analytics required need to be much more sophisticated than has traditionally been the case, and the systems need access to a much broader set of data.
Our belief is that businesses need to combat this threat by analysing their own data, building data platforms, conducting data engineering to extract and transform their data, and using data science and AI skills to extract value from this data. Once a risk is identified, it should be closed with a report or dashboard to identify and alert on future instances of the risk.
Though more modern fincrime technology is coming to market with a better story in this area, off the shelf software is still sub-optimal compared with building your own data and analytics capability similar to that outlined above. By analysing your own data, you will have total flexibility and ability to adapt to new and changing threats without any dependency on a third party vendor.
Ensemble are a professional services business who are helping our customers build these type of capabilities, augmenting and develop their own next generation fraud detection and prevention technology. We combine cloud technology platform expertise, data and AI skills with industry knowledge to drive innovation and ultimately combat financial crime. Please reach out to us for an informal discussion.